简单介绍一下:
老王是个新人,心血来潮想用java试试写爬虫,完全零基础,搜了很多教程,往往因为作者水平太高,不能一下子理解大佬代码中的深意,并且有些看似很简单的东西,对于我这种菜鸟来说,其实是很难解决的错误或者是异常。故,在稍有心得后,写下此篇。从最基础开始。一步一步,从小菜鸟,成为稍微大一点的菜鸟,给初学者带来一点启示。
如果只需要全部的代码,请直接拉至最后
如果转载,请注明出处:https://blog.csdn.net/qq_37893828/article/details/88072761 ——会飞的王浩然
如有疏漏之处,欢迎留言指出
往期列表:更多详细解释请从第一弹翻阅
- java爬虫入门第一弹——从百度首页开始(欢迎浏览)
- java爬虫入门第二弹——通过URL下载图片(以下载百度logo为例)(欢迎浏览)
- java爬虫入门第三弹——正则表达式简单应用(抓取豆瓣读书信息并以文本文件输出)(欢迎浏览)
这一节我们的目标
下载下来百度首页的源代码:即当你在浏览器打开百度首页,右键选择查看源代码之后,弹出来的那一堆东西
java_15">从最基础开始,我首先假设你什么都不会,只会一点点的C语言和java编程
- 第一步:创建java工程,并且在main函数中用string字符串存入你即将要爬取的URL,并创建URL对象
java"> public class Main {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
//定义字符串用来存取即将爬取的网络地址
String urlString="http://www.baidu.com";
//构造URL对象
URL url=new URL(urlString);
}
}
- 什么是URL:即统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
- 我们把百度首页这个页面看做一种资源,那么百度首页的网址就是这个我们要定义的URL
- 关于URL地址的定义:我们平时访问百度首页的时候,都是直接输入“www.baidu.com”,或者输入“baidu.com”都可以访问百度的主页,但是在我们进去之后你会发现,这个网址变成了下面这个样子,它在最前面多了“http://”,这个东西,这个东西是什么呢,这个表示超文本传输协议,简单理解就是网站传输数据用到的一种协议,在浏览器上会自动检测缺失的东西给你在你给的地址前面添加上这个协议的名称,但是在java中,没有浏览器给你添加这个,所以我们在自己写爬虫的时候一定要注意这个简单的错误
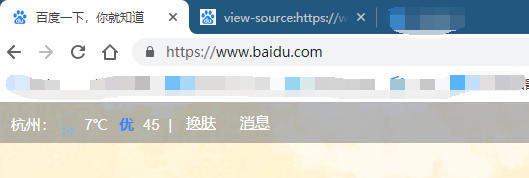
- 一个简单的解决办法是:首先在浏览器中打开这个地址,然后复制粘贴(在前面的学习中,这个方法是最好用的)
- 第二步:链接到URL,并创建数据流
代码按照顺序粘贴在main函数中即可
java"> //连接到URL
HttpURLConnection httpURLConnection=(HttpURLConnection)url.openConnection();
//创建数据流
//获取数据,并以字节的形式放在缓冲区
InputStream inputStream=httpURLConnection.getInputStream();
//使用指定字符集将字节流转换到字符流
InputStreamReader inputStreamReader=new InputStreamReader(inputStream);
//将字符流放入缓存里,如果缓存满了,就读入内存,这个类存在的作用是为了提高读的效率
BufferedReader bufferedReader=new BufferedReader(inputStreamReader);
- “HttpURLConnection”这个类顾名思义,就是连接通过HTTP协议连接URL所指向的地址,但是并没有开始获取数据
- “HttpURLConnection.getInputStream”这个方法的作用才是从URL中获取数据
- **第三步:**从字符流中读取数据并输出抓取到的百度首页
代码按照顺序粘贴在main函数中即可
java"> //从字符流中读取数据
String lineString;
String htmlString="";
while((lineString=bufferedReader.readLine())!=null) {
htmlString+=lineString;
}
//输出页面
System.out.println(htmlString);
- 这一步类似于C语言中的“scanf”循环输入,学过c语言的初学者应该很容易看明白
- “readLine()”这个方法顾名思义就是按行读取数据的意思
//C语言,仅做解说使用
int a,b;
while((scanf(%d%d,a,b)!=EOF){}
- 在这一步中,“String HTMLString”更好的方法是使用“StringBuffer”或者是“StringBuilder”,这两种方法的详细区别
- 三种方法的区别首先是运行速度:StringBuilder > StringBuffer > String,至于区别请读者自行百度,此处不再赘述,而之所以选用String的原因是因为足够基础
- 而在大规模的爬取数据时候,为了追求效率,首要的选择应该是“StringBuffer”和“StringBuilder”,但是在多线程的时候下StringBuilder则是不合适的,在以后涉及到多线程的时候会提及
全部代码
java">import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class Main {
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
//定义字符串用来存取即将爬取的网络地址
String urlString="http://www.baidu.com";
//构造URL对象
URL url=new URL(urlString);
//连接到URL
HttpURLConnection httpURLConnection=(HttpURLConnection)url.openConnection();
//创建数据流
//获取数据,并以字节的形式放在缓冲区
InputStream inputStream=httpURLConnection.getInputStream();
//使用指定字符集将字节流转换到字符流
InputStreamReader inputStreamReader=new InputStreamReader(inputStream);
//将字符流放入缓存里,如果缓存满了,就读入内存,这个类存在的作用是为了提高读的效率
BufferedReader bufferedReader=new BufferedReader(inputStreamReader);
//从字符流中读取数据
String lineString;
String htmlString="";
while((lineString=bufferedReader.readLine())!=null) {
htmlString+=lineString;
}
//输出页面
System.out.println(htmlString);
}
}
输出结果





